
The University of Michigan Herbarium is home to some of the finest botanical collections in the world. Founded in 1837 and growing ever since, their 1.7 million specimens of vascular plants, algae, bryophytes, fungi, and lichens, combined with the expertise of the faculty-curators, students, and staff, provide a world-class facility for teaching and research in systematic biology and biodiversity studies. Digitizing accurate information about that many specimens can be challenging. How could they use new technologies like AI to help speed up and reduce human error in their digitizing process?
Ph.D. student Will Weaver, in collaboration with Research Museum Collection Manager and Assistant Research Scientist Brad Ruhfel, Professor Stephen Smith, and project manager Kyle Lough, all in LSA’s Department of Ecology & Evolutionary Biology, developed a Python-based application suite called VoucherVision to help speed up their digital workflow while reducing human error:
- Use LeafMachine2 to isolate just the text components of the image of the specimen labels.
- Interpret that text using optical character recognition (OCR). The default is Google Vision OCR, but in practice, the free vision language models Florence-2 and Qwen2-VL-7B-Instruct have proved to be more accurate with handwriting.
- Standardize the output into a consistent JavaScript Object Notation (JSON) format with the VoucherVision suite using large language models (LLMs), such as the U-M GPT Toolkit, including U-M Maizey. Each LLM prompt contains detailed formatting instructions, and they can include OCR from multiple engines in a single prompt to draw on the strengths of different OCR engines.
- Review the JSON for accuracy. Edit as needed.
- Import that formatted data into the Specify Collection Management Platform. Specify is a database-driven application for biologically-based collection objects that the Herbarium, along with the U-M Museum of Paleontology and the U-M Museum of Zoology, use heavily.
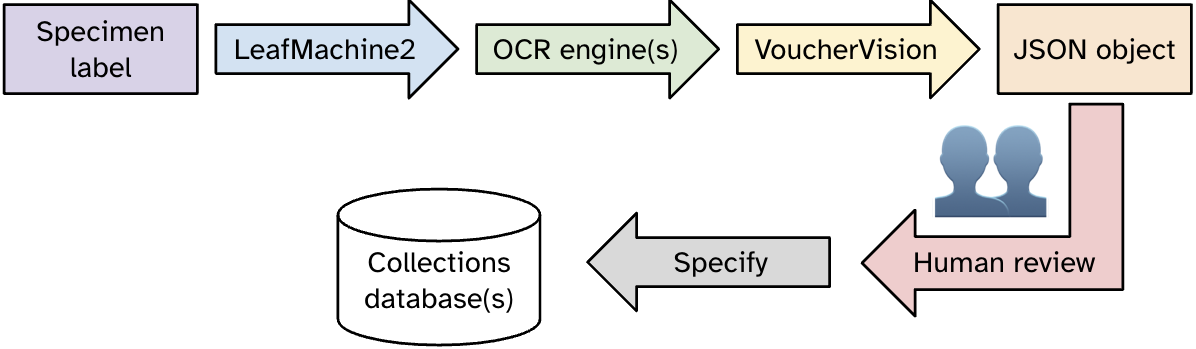
Example workflow from scanning the specimen label to creating the database record.
The VoucherVision suite itself consists of three major components:
- Streamlit provides a user-friendly GUI to use the suite.
- VoucherVision harnesses the power of LLMs to transform the transcription process of natural history specimen labels.
- VoucherVisionEditor allows the user to edit and manage the label transcriptions generated by VoucherVision efficiently.
VoucherVision uses the U-M GPT Toolkit, but it also includes support for OpenAI API, Google PaLM 2, Google Gemini, local LLMs (such as Mixtral and Meta Llama 2), and private OpenAI via Azure to make it more universal for others to use as an open-source project.
While the U-M Herbarium has not deployed VoucherVision at scale yet, our initial calculations suggest that it reduces overall transcription costs by 40–60%. In addition to immediate cost and time savings, the automation frees up valuable time for researchers to focus on more complex tasks and analyses.
Researchers across more than a dozen campuses and museums are using VoucherVision in collaboration with our Herbarium collection managers. For more information about or to participate in testing VoucherVision, please fill out their Google Form.